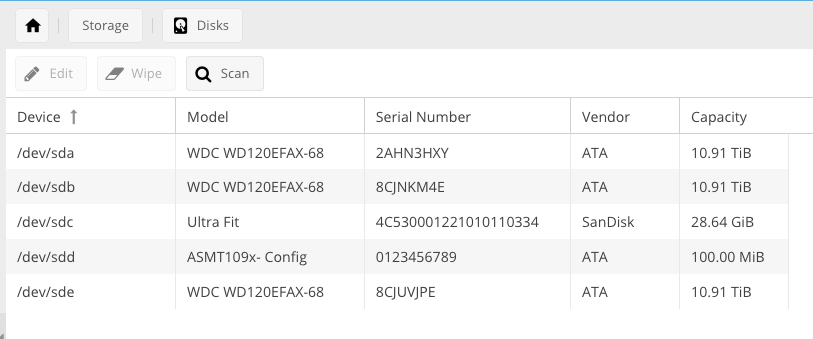
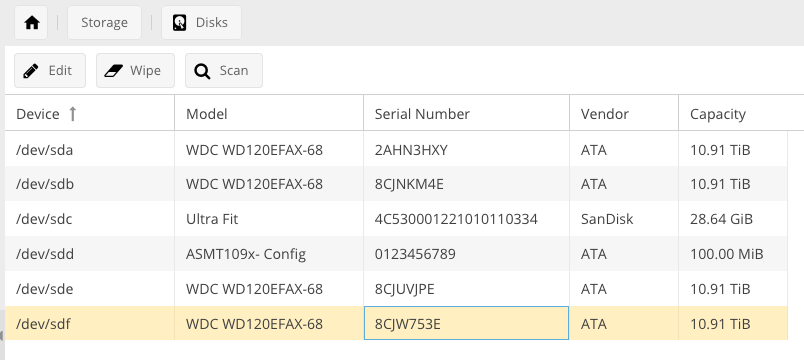
Hi, I have an issue with my RAID10 in my OMV 4.1.36-1. I don't know what happened. I have noticed that only 3 out of 4 discs are working and in Raid Managment the status is active/degraded. I use 4 x 12TB WD Red disks.
Any help from you is appreciated.
Thank you very much.
Code
root@pandora:~# cat /proc/mdstat
Personalities : [raid10] [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4]
md0 : active raid10 sda[0] sde[2] sdb[1]
23437508608 blocks super 1.2 512K chunks 2 near-copies [4/3] [UUU_]
bitmap: 82/175 pages [328KB], 65536KB chunk
unused devices: <none>Code
root@pandora:~# blkid
/dev/sda: UUID="8b767a7d-c52c-068d-c04f-1a3cfd8d4c5f" UUID_SUB="3904f2f1-fe1f-bde3-a965-d9dbe0074f66" LABEL="pandora:Raid4x12TBWdRed" TYPE="linux_raid_member"
/dev/md0: LABEL="REDRAID4X12" UUID="5fd65f52-b922-45e3-a940-eb7c75460446" TYPE="ext4"
/dev/sdb: UUID="8b767a7d-c52c-068d-c04f-1a3cfd8d4c5f" UUID_SUB="a6bb8aa8-4e9b-7f90-b105-45a9301acbce" LABEL="pandora:Raid4x12TBWdRed" TYPE="linux_raid_member"
/dev/sdc1: UUID="2218-DC43" TYPE="vfat" PARTUUID="09f69470-ba7b-4b6b-9456-c09f4c6ad2ee"
/dev/sdc2: UUID="87bfca96-9bee-4725-ae79-d8d7893d5a49" TYPE="ext4" PARTUUID="3c45a8f0-3106-4ba8-89bc-b15d22e81144"
/dev/sdc3: UUID="856b0ba6-a0a9-49f2-81ef-27e24004aa98" TYPE="swap" PARTUUID="fda4b444-cf82-4ae8-b916-01b8244acee3"
/dev/sde: UUID="8b767a7d-c52c-068d-c04f-1a3cfd8d4c5f" UUID_SUB="6c9c5433-6838-c39f-abfa-7807205a3238" LABEL="pandora:Raid4x12TBWdRed" TYPE="linux_raid_member"Code
root@pandora:~# fdisk -l | grep "Disk "
Disk /dev/sda: 10,9 TiB, 12000138625024 bytes, 23437770752 sectors
Disk /dev/sdb: 10,9 TiB, 12000138625024 bytes, 23437770752 sectors
Disk /dev/md0: 21,8 TiB, 24000008814592 bytes, 46875017216 sectors
Disk /dev/sdc: 28,7 GiB, 30752636928 bytes, 60063744 sectors
Disk identifier: 51328880-3F36-4C4F-A18D-76E5CF56DD7D
Disk /dev/sdd: 100 MiB, 104857600 bytes, 204800 sectors
Disk /dev/sde: 10,9 TiB, 12000138625024 bytes, 23437770752 sectorsCode
root@pandora:~# cat /etc/mdadm/mdadm.conf
# mdadm.conf
#
# Please refer to mdadm.conf(5) for information about this file.
#
# by default, scan all partitions (/proc/partitions) for MD superblocks.
# alternatively, specify devices to scan, using wildcards if desired.
# Note, if no DEVICE line is present, then "DEVICE partitions" is assumed.
# To avoid the auto-assembly of RAID devices a pattern that CAN'T match is
# used if no RAID devices are configured.
DEVICE partitions
# auto-create devices with Debian standard permissions
CREATE owner=root group=disk mode=0660 auto=yes
# automatically tag new arrays as belonging to the local system
HOMEHOST <system>
# definitions of existing MD arrays
ARRAY /dev/md0 metadata=1.2 name=pandora:Raid4x12TBWdRed UUID=8b767a7d:c52c068d:c04f1a3c:fd8d4c5f