I am waiting for my hardware appliance parts to show.. So I built OpenMediaVault as VM on my VMWare cluster.
1CPU
1GB RAM
2 x 1Gb NIC
1 x 64GB SSD for OS
3 x 100GB SSD for RAID 5
I set and .. besides expected querks about SMB / NFS interactions on permissions (still working on those .. but kind of expected these as ACL to POSIX is a PITA)
My goal though was to test out RAID recovery steps and how clean / what tools they needed to do that.
First Test: Add a new hard disk and expand
Super easy.. 4.5 out of 5 on how simple this was. Only note is that it took me a few min to find details of % rebuild such that the new array size would be ready
Second Test: Replace a Drive
While system running... pull a hard disk and then recover.
At first this did ok.. Remove disk /dev/sdc Array still worked.. just noted critical state. But then I added back a new 150GB disk and it showed up as /dev/sdc (expected it as /dev/sde but ... meh..)
Rebuild -> Wizard was fine.. seemed to be chugging along ok.
Third Test: Hard Power during rebuild.
This is the last test I typically do where the array is in rebuild mode... and you just pull power on server. It then has to handle OS boot recovery as well as decide what to do with Array Ex: /dev/md0 when it is still critical but rebuild started, yet not complete.
Boot state was file system offline
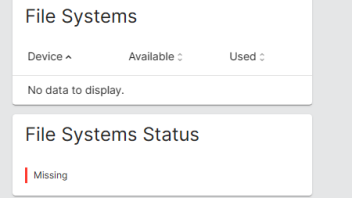
But more concerning is it is not even listing the RAID device
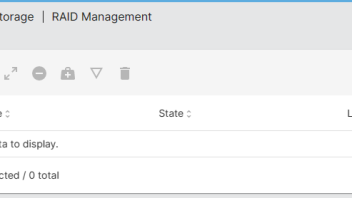
This
root@pandora:~# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid1] [raid10]
md0 : inactive sde[3] sdd[2] sdb[0] sdc[4]
471599104 blocks super 1.2
unused devices: <none>
is where things went off rails.
1) OS Boot... fsck repaired file system on /dev/sda boot drive partitions - Good
2) System booted up and UI launched etc... - Good
3) All disk showing up - Good
4) /dev/md0 repair continue but while this is happening... services come online - Fail
Trying to root cause as well as document how to recover the system. Maybe this is already posted as a "how to repair a RAID state" in a document flow or video... but I did not see it.
## dmeg state <snip> to just drive messages
[ 1.660977] ata1.00: ATAPI: VMware Virtual IDE CDROM Drive, 00000001, max UDMA/33
[ 1.666086] scsi 1:0:0:0: CD-ROM NECVMWar VMware IDE CDR00 1.00 PQ: 0 ANSI: 5
[ 1.675319] sd 0:0:0:0: [sda] 134217728 512-byte logical blocks: (68.7 GB/64.0 GiB)
[ 1.675333] sd 0:0:0:0: [sda] Write Protect is off
[ 1.675335] sd 0:0:0:0: [sda] Mode Sense: 61 00 00 00
[ 1.675349] sd 0:0:0:0: [sda] Cache data unavailable
[ 1.675351] sd 0:0:0:0: [sda] Assuming drive cache: write through
[ 1.675614] sd 0:0:1:0: [sdb] 209715200 512-byte logical blocks: (107 GB/100 GiB)
[ 1.675627] sd 0:0:1:0: [sdb] Write Protect is off
[ 1.675629] sd 0:0:1:0: [sdb] Mode Sense: 61 00 00 00
[ 1.675641] sd 0:0:1:0: [sdb] Cache data unavailable
[ 1.675643] sd 0:0:1:0: [sdb] Assuming drive cache: write through
[ 1.675861] sd 0:0:2:0: [sdc] 314572800 512-byte logical blocks: (161 GB/150 GiB)
[ 1.675874] sd 0:0:2:0: [sdc] Write Protect is off
[ 1.675875] sd 0:0:2:0: [sdc] Mode Sense: 61 00 00 00
[ 1.675887] sd 0:0:2:0: [sdc] Cache data unavailable
[ 1.675888] sd 0:0:2:0: [sdc] Assuming drive cache: write through
[ 1.676098] sd 0:0:3:0: [sdd] 209715200 512-byte logical blocks: (107 GB/100 GiB)
[ 1.676110] sd 0:0:3:0: [sdd] Write Protect is off
[ 1.676112] sd 0:0:3:0: [sdd] Mode Sense: 61 00 00 00
[ 1.676123] sd 0:0:3:0: [sdd] Cache data unavailable
[ 1.676125] sd 0:0:3:0: [sdd] Assuming drive cache: write through
[ 1.678553] sd 0:0:4:0: [sde] 209715200 512-byte logical blocks: (107 GB/100 GiB)
[ 1.678576] sd 0:0:4:0: [sde] Write Protect is off
[ 1.678578] sd 0:0:4:0: [sde] Mode Sense: 61 00 00 00
[ 1.678600] sd 0:0:4:0: [sde] Cache data unavailable
[ 1.678602] sd 0:0:4:0: [sde] Assuming drive cache: write through
[ 1.689953] sda: sda1 sda2 < sda5 >
[ 1.704065] sd 0:0:2:0: [sdc] Attached SCSI disk
[ 1.704096] sd 0:0:0:0: [sda] Attached SCSI disk
[ 1.704133] sd 0:0:1:0: [sdb] Attached SCSI disk
[ 1.707367] random: fast init done
[ 1.716059] sd 0:0:3:0: [sdd] Attached SCSI disk
[ 1.716263] sd 0:0:4:0: [sde] Attached SCSI disk
[ 1.718926] sr 1:0:0:0: [sr0] scsi3-mmc drive: 1x/1x writer dvd-ram cd/rw xa/form2 cdda tray
[ 1.718929] cdrom: Uniform CD-ROM driver Revision: 3.20
[ 1.799911] raid6: sse2x4 gen() 12636 MB/s
[ 1.867915] raid6: sse2x4 xor() 7265 MB/s
[ 1.935914] raid6: sse2x2 gen() 13208 MB/s
[ 2.003916] raid6: sse2x2 xor() 8459 MB/s
[ 2.071921] raid6: sse2x1 gen() 9450 MB/s
[ 2.139915] raid6: sse2x1 xor() 6012 MB/s
[ 2.139921] raid6: using algorithm sse2x2 gen() 13208 MB/s
[ 2.139922] raid6: .... xor() 8459 MB/s, rmw enabled
[ 2.139924] raid6: using ssse3x2 recovery algorithm
[ 2.140928] xor: automatically using best checksumming function avx
[ 2.141476] async_tx: api initialized (async)
[ 2.150874] md/raid:md0: not clean -- starting background reconstruction
[ 2.150895] md/raid:md0: device sde operational as raid disk 3
[ 2.150897] md/raid:md0: device sdd operational as raid disk 2
[ 2.150898] md/raid:md0: device sdb operational as raid disk 0
[ 2.151793] md/raid:md0: cannot start dirty degraded array.
[ 2.151954] md/raid:md0: failed to run raid set.
[ 2.151955] md: pers->run() failed ...
[ 2.172145] sr 1:0:0:0: Attached scsi CD-ROM sr0
[ 2.332210] Btrfs loaded, crc32c=crc32c-intel, zoned=yes
[ 2.404732] PM: Image not found (code -22)
[ 3.594298] EXT4-fs (sda1): mounted filesystem with ordered data mode. Opts: (null). Quota mode: none.
[ 3.671619] Not activating Mandatory Access Control as /sbin/tomoyo-init does not exist.
[ 3.798104] systemd[1]: Inserted module 'autofs4'
## lsblk -->> Uh?!?! no "md0" ?????!!
root@pandora:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 64G 0 disk
├─sda1 8:1 0 63G 0 part /
├─sda2 8:2 0 1K 0 part
└─sda5 8:5 0 975M 0 part [SWAP]
sdb 8:16 0 100G 0 disk
sdc 8:32 0 150G 0 disk
sdd 8:48 0 100G 0 disk
sde 8:64 0 100G 0 disk
sr0 11:0 1 800M 0 rom
## mdadm config ** Not sure about it listing spare=1 as capacity with 3 x 100GB and 1 x 150GB Disk = 294GB usable capacity... so... I think this is not correct
root@pandora:~# cat /etc/mdadm/mdadm.conf
# This file is auto-generated by openmediavault (https://www.openmediavault.org)
# WARNING: Do not edit this file, your changes will get lost.
# mdadm.conf
# Please refer to mdadm.conf(5) for information about this file.
# by default, scan all partitions (/proc/partitions) for MD superblocks.
# alternatively, specify devices to scan, using wildcards if desired.
# Note, if no DEVICE line is present, then "DEVICE partitions" is assumed.
# To avoid the auto-assembly of RAID devices a pattern that CAN'T match is
# used if no RAID devices are configured.
DEVICE partitions
# auto-create devices with Debian standard permissions
CREATE owner=root group=disk mode=0660 auto=yes
# automatically tag new arrays as belonging to the local system
HOMEHOST <system>
# definitions of existing MD arrays
ARRAY /dev/md0 metadata=1.2 spares=1 name=pandora:0 UUID=ec57ee88:ec272e66:dba45014:18600360
## RAID status
root@pandora:~# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Dec 2 12:13:02 2021
Raid Level : raid5
Used Dev Size : 104791040 (99.94 GiB 107.31 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sun Dec 5 23:28:18 2021
State : active, FAILED, Not Started
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : unknown
Name : pandora:0 (local to host pandora)
UUID : ec57ee88:ec272e66:dba45014:18600360
Events : 1129
Number Major Minor RaidDevice State
- 0 0 0 removed
- 0 0 1 removed
- 0 0 2 removed
- 0 0 3 removed
- 8 64 3 sync /dev/sde
- 8 32 1 spare rebuilding /dev/sdc
- 8 48 2 sync /dev/sdd
- 8 16 0 sync /dev/sdb
root@pandora:~#
# Is RAID still recovering and so .. just wait... nope.... I left this run all night and no change
root@pandora:~# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid1] [raid10]
md0 : inactive sde[3] sdd[2] sdb[0] sdc[4]
471599104 blocks super 1.2
unused devices: <none>
# Kick rebuild in pants (no option in GUI as it did not list md device
root@pandora:~# mdadm --assemble --run --force --update=resync /dev/md0 /dev/sdb /dev/sdc /dev/sdd /dev/sde
mdadm: Marking array /dev/md0 as 'clean'
mdadm: /dev/md0 has been started with 3 drives (out of 4) and 1 rebuilding.
# Recheck block device listing /md0 is back...
root@pandora:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 64G 0 disk
├─sda1 8:1 0 63G 0 part /
├─sda2 8:2 0 1K 0 part
└─sda5 8:5 0 975M 0 part [SWAP]
sdb 8:16 0 100G 0 disk
└─md0 9:0 0 299.8G 0 raid5
sdc 8:32 0 150G 0 disk
└─md0 9:0 0 299.8G 0 raid5
sdd 8:48 0 100G 0 disk
└─md0 9:0 0 299.8G 0 raid5
sde 8:64 0 100G 0 disk
└─md0 9:0 0 299.8G 0 raid5
Now back in GUI
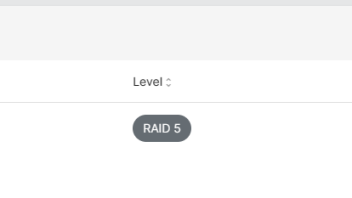
Now that looks better
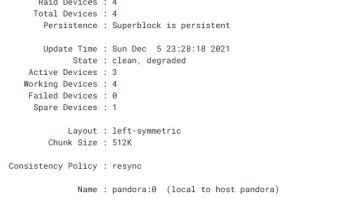
# With RAID back online.. do we restart file system or UI services to accept status now repairing
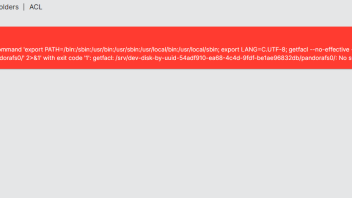
*maybe above error is not related... this is back to querks of ACL and POSIX I have not vetted out how the system is doing this.
Quesetions:
1) I know this is a bit hostile, but to trust my data, I need to know recovery expectations and paths. Why did it get stuck, and is there a miss configuration of UI / tool set on my part?
2) Is there a better "flow diagram" of repair pinned /posted that helps people review from base hardware to full volume back online.
Thanks,
