

Hello OMV team!
First of all, thank you very much for all your efforts to make your awesome system greater and greater every day. I'm using it from the 2.X version and i'm really happy with all the UX and confort that it provides.
Our case is that we're using right now your system in our small company for manage our data server. It's 24/7 and we never have had issues. Yesterday, we made a shutdown of the server to upgrade the RAM from 16GB to 32GB to improve performance in our use case, and after power on, one of the RAIDs of the system is marked like "Missing" and it can't be mounted again.
In the following points I'll try to explain our configuration:
OS Version: OMV 4.X
Number of disks: 1x SSD of 250GB for the OS and 8x HDDs of 6TB each one for mounting 2x RAID5
This two RAIDs are:
- 1) Label: "RAID5" type: RAID5 disks: sda sdb sdc sdd
- 2) Label: "RAID5B" type: RAID5 disks: sde sdf sdg sdh
The issue is with the raid labeled as "RAID5". After the reboot it doesn't appear listed on the RAID section of your frontend and when I go to the FileSystem tab it appears like "Missing".
On the S.M.A.R.T. tab you can see that the "sdb" disk is marked as faulty. Making some checks/tests we determine that the disk must be fully broken because it doesn't appear in some of the debug commands.
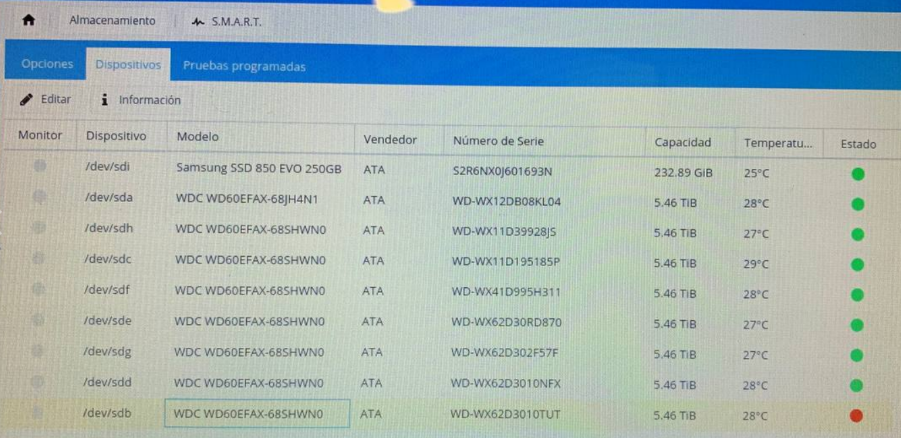
Following the information and commands mentioned in this post: Degraded or missing raid array questions, you can find below the obtained information.
--------------------------------------
$ cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid1] [raid10]
md0 : inactive sda[4](S) sdd[3](S) sdc[2](S)
17581171464 blocks super 1.2
md1 : active raid5 sde[0] sdf[1] sdg[2] sdh[3]
17581171200 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
bitmap: 0/44 pages [0KB], 65536KB chunk
unused devices: <none>
--------------------------------------
$ blkid
/dev/sdh: UUID="401f4331-dab4-9eea-f7af-c2017f49fd53" UUID_SUB="93afa8c8-5c7f-d9e3-bcf4-303b61acea49" LABEL="ken:RAID5B" TYPE="linux_raid_member"
/dev/sdd: UUID="1dddc47a-5264-43ca-c826-044f2ec26555" UUID_SUB="40ec61b7-7036-5895-0337-43168ec9158d" LABEL="ken:RAID5" TYPE="linux_raid_member"
/dev/sdg: UUID="401f4331-dab4-9eea-f7af-c2017f49fd53" UUID_SUB="3928383f-7392-07d7-ee8a-262bc47ca70c" LABEL="ken:RAID5B" TYPE="linux_raid_member"
/dev/sda: UUID="1dddc47a-5264-43ca-c826-044f2ec26555" UUID_SUB="28cf8950-2cc0-60b7-06a4-c1a44c555039" LABEL="ken:RAID5" TYPE="linux_raid_member"
/dev/sdc: UUID="1dddc47a-5264-43ca-c826-044f2ec26555" UUID_SUB="a7d856ad-ac8f-64b4-010a-c8a7fb7cdf8a" LABEL="ken:RAID5" TYPE="linux_raid_member"
/dev/sde: UUID="401f4331-dab4-9eea-f7af-c2017f49fd53" UUID_SUB="95d7874a-d5fe-5000-b76e-030779c6a37b" LABEL="ken:RAID5B" TYPE="linux_raid_member"
/dev/sdf: UUID="401f4331-dab4-9eea-f7af-c2017f49fd53" UUID_SUB="b5bffb90-28ce-3736-a218-23abbce50a7d" LABEL="ken:RAID5B" TYPE="linux_raid_member"
/dev/sdi1: UUID="a682f238-3c95-4f4d-a097-ab2b39bd86a2" TYPE="ext4" PARTUUID="56ab785c-01"
/dev/sdi5: UUID="38631c0a-fb19-488c-a928-16b2370efa0b" TYPE="swap" PARTUUID="56ab785c-05"
/dev/md1: LABEL="RAID5B" UUID="d1a508ab-7776-4b96-a7d6-a54fe8de1f09" TYPE="ext4"
-----------------------------
$ fdisk -l | grep "Disk "
Disk /dev/sdh: 5,5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFAX-68S
Disk /dev/sdd: 5,5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFAX-68S
Disk /dev/sdg: 5,5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFAX-68S
Disk /dev/sdb: 5,5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFAX-68S
Disk /dev/sda: 5,5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFAX-68J
Disk /dev/sdc: 5,5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFAX-68S
Disk /dev/sde: 5,5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFAX-68S
Disk /dev/sdf: 5,5 TiB, 6001175126016 bytes, 11721045168 sectors
Disk model: WDC WD60EFAX-68S
Disk /dev/sdi: 232,9 GiB, 250059350016 bytes, 488397168 sectors
Disk model: Samsung SSD 850
Disklabel type: dos
Disk identifier: 0x56ab785c
Disk /dev/md1: 16,4 TiB, 18003119308800 bytes, 35162342400 sectors
----------------------
$ cat /etc/mdadm/mdadm.conf
# This file is auto-generated by openmediavault (https://www.openmediavault.org)
# WARNING: Do not edit this file, your changes will get lost.
# mdadm.conf
#
# Please refer to mdadm.conf(5) for information about this file.
#
# by default, scan all partitions (/proc/partitions) for MD superblocks.
# alternatively, specify devices to scan, using wildcards if desired.
# Note, if no DEVICE line is present, then "DEVICE partitions" is assumed.
# To avoid the auto-assembly of RAID devices a pattern that CAN'T match is
# used if no RAID devices are configured.
DEVICE partitions
# auto-create devices with Debian standard permissions
CREATE owner=root group=disk mode=0660 auto=yes
# automatically tag new arrays as belonging to the local system
HOMEHOST <system>
# instruct the monitoring daemon where to send mail alerts
MAILADDR XXX@XXX.com
MAILFROM root
# definitions of existing MD arrays
ARRAY /dev/md0 metadata=1.2 name=ken:RAID5 UUID=1dddc47a:526443ca:c826044f:2ec26555
ARRAY /dev/md1 metadata=1.2 name=ken:RAID5B UUID=401f4331:dab49eea:f7afc201:7f49fd53
--------------------------
$ mdadm --detail --scan --verbose
ARRAY /dev/md1 level=raid5 num-devices=4 metadata=1.2 name=ken:RAID5B UUID=401f4331:dab49eea:f7afc201:7f49fd53
devices=/dev/sde,/dev/sdf,/dev/sdg,/dev/sdh
INACTIVE-ARRAY /dev/md0 num-devices=3 metadata=1.2 name=ken:RAID5 UUID=1dddc47a:526443ca:c826044f:2ec26555
devices=/dev/sda,/dev/sdc,/dev/sdd
-------------------------------
Surfing on your forums I discovered this other post: OMV Raid lost after a power hit with a similar problem. The difference is in the disk failure...
Knowing our disk failure, we just replaced the disk with a new one and then, in the S.M.A.R.T. tab, everything appears green, but the RAID is yet not mounted and marked as missing...
I put in the next answer to this post the same commands information but after the replacement of the faulty disk:
In the related post that we found one of the moderators answered this:
"""
Try stopping and reassembling;
mdadm --stop /dev/md0
mdadm --assemble --force --verbose /dev/md0 /dev/sd[bcde]
no guarantee, but that usually works
"""
We haven't tried this yet because we are not sure if the same command is applicable in our case with the faulty disk replaced OR if it's better to launch this command with only the 3 remaining disks to try to get a "deprecated" RAID state and after that, go further and add the new disk as we have done other times.
What do you think? Any advice? We have a backup in other server but could be really time expensive to restore it... so if there is some way to recover the current one will be great!
Thank you so much in advance for your support.
Best regards,
Carlos